实时模型对比
在 Stagehand Evals Dashboard 上查看不同 LLM 的实时性能对比。
文档索引
可在此获取完整文档索引:https://docs.stagehand.dev/llms.txt
在进一步浏览前,可使用该文件发现所有可用页面。
监控性能、优化成本,并评估 LLM 的效果
评估可以帮助你了解自动化执行得有多好、哪些模型最适合你的使用场景,以及如何在成本与可靠性之间做优化。本指南同时涵盖如何监控你自己的工作流,以及如何运行更全面的评估。
实时模型对比
在 Stagehand Evals Dashboard 上查看不同 LLM 的实时性能对比。
评估可以帮助你系统化地测试并改进自动化工作流。Stagehand 同时提供内置评估,以及用于创建自定义评估的工具。
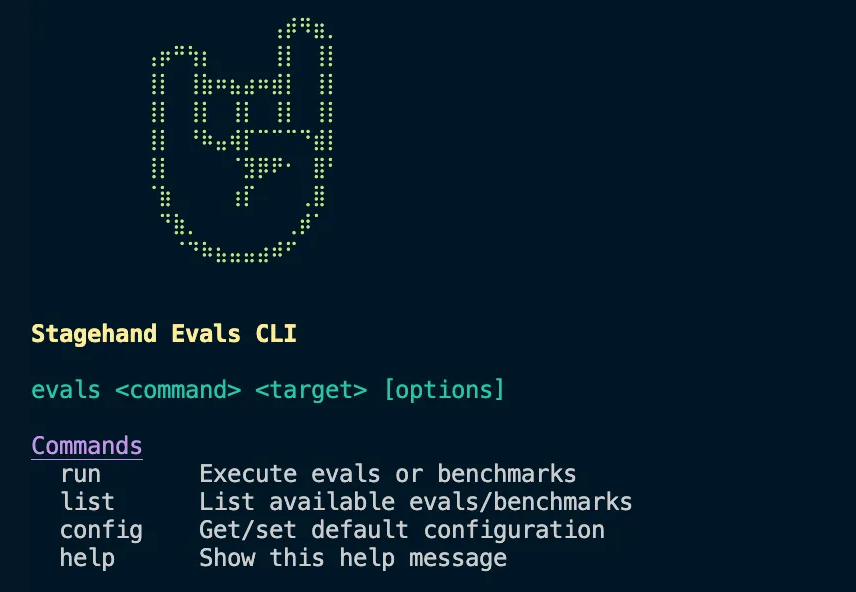
Stagehand CLI 为运行评估提供了强大的接口。你可以使用可自定义的设置来运行特定 eval、某个类别,或外部基准测试。
Evals 被分为:
act 方法功能的 eval。extract 方法功能的 eval。observe 方法功能的 eval。act、extract 和 observe 方法功能的 eval。agent 功能的 eval。安装依赖
# 在 stagehand 根目录中pnpm install构建 CLI
pnpm run build:cli验证安装
evals help# 运行全部 evalevals run all
# 运行特定类别evals run actevals run extractevals run observeevals run agent
# 运行特定 evalevals run extract/extract_text
# 列出可用 evalevals listevals list --detailed
# 配置默认值evals configevals config set env browserbaseevals config set trials 5-e, --env:环境(local 或 browserbase)-t, --trials:每个 eval 的试验次数(默认:3)-c, --concurrency:最大并行会话数(默认:10)-m, --model:覆盖默认模型-p, --provider:覆盖默认提供商--api:使用 Stagehand API,而不是 SDKCLI 支持多种行业标准基准测试:
# 带筛选条件的 WebBenchevals run benchmark:webbench -l 10 -f difficulty=easy -f category=READ
# GAIA 基准测试evals run b:gaia -s 100 -l 25 -f level=1
# WebVoyagerevals run b:webvoyager -l 50
# OnlineMind2Webevals run b:onlineMind2Web
# OSWorldevals run b:osworld -f source=Mind2Web你可以在 evals/tasks 中查看具体的 eval。每个 eval 都会根据 evals/evals.config.json 被归入相应的评估类别。
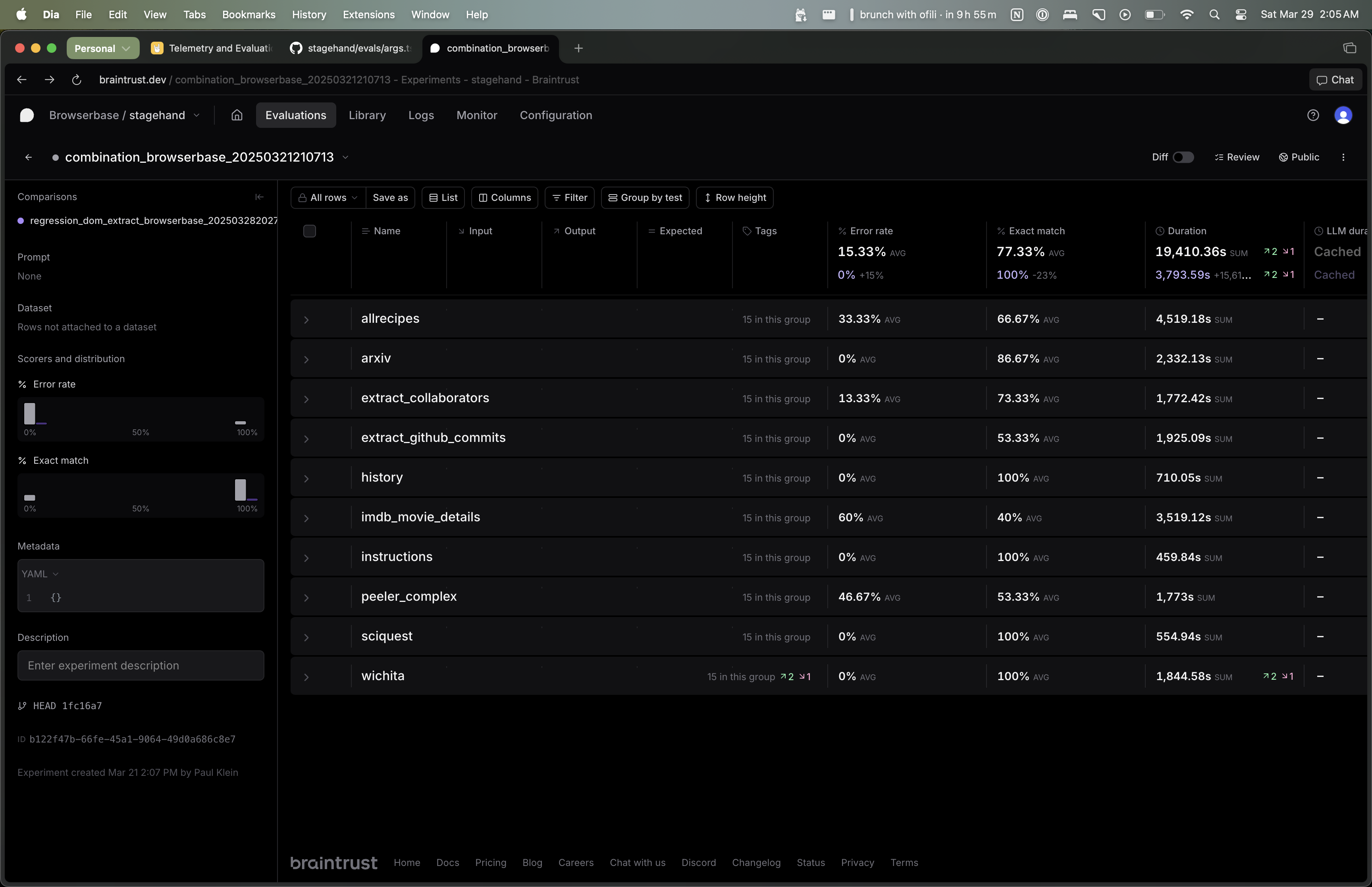
评估结果可以在 Braintrust 上查看。运行 npm run evals 时,你可以根据终端中显示的 Braintrust URL 查看某个特定 eval 的结果。
默认情况下,每个 eval 会针对每个模型运行五次。“Exact Match” 列显示该 eval 判定正确的百分比;“Error Rate” 列显示该 eval 出错的百分比。
你可以使用 Braintrust UI 按模型或 eval 进行筛选,并聚合所有 eval 的结果。
创建评估文件
在 evals/tasks/your-eval.ts 中创建一个新文件:
import { EvalTask } from '../types';
export const customEvalTask: EvalTask = { name: 'custom_task_name', description: '测试特定的自动化工作流',
// 测试准备 setup: async ({ page }) => { await page.goto('https://example.com'); },
// 实际测试 task: async ({ stagehand, page }) => { // 你的自动化逻辑 await stagehand.act({ action: 'click the login button' }); const result = await stagehand.extract({ instruction: 'Get the user name', schema: { username: 'string' } }); return result; },
// 验证 validate: (result, expected) => { return result.username === expected.username; },
// 测试用例 testCases: [ { input: { /* 测试输入 */ }, expected: { username: 'john_doe' } } ],
// 评估标准 scoring: { exactMatch: true, timeout: 30000, retries: 2 }};添加到配置中
更新 evals/evals.config.json:
{ "categories": { "custom": ["custom_task_name"], "existing_category": ["custom_task_name"] }}运行你的评估
# 测试你的自定义评估evals run custom_task_name
# 运行整个自定义类别evals run custom
# 以特定设置运行evals run custom_task_name -e browserbase -t 5 -m gpt-4o症状:测试因超时错误而失败。
解决方案:
taskConfig.ts 中的超时时间症状:同一个测试随机通过或失败。
解决方案:
症状:token 使用量超出预算。
解决方案:
症状:结果没有上传到仪表板。
解决方案: